Do you want to accelerate your incident response and ensure business continuity? With the powerful integration of cloud observability and DevOps processes, this can easily be made a reality.
In today’s competitive landscape, downtime and delays can significantly impact your bottom line. That’s why optimizing your incident response is crucial.
In this blog, we will explore how combining cloud observability with DevOps methodologies can empower your organization to swiftly detect, diagnose, and resolve issues in the cloud environment.
We will also go deeper into the key strategies and benefits that drive faster, more accurate incident response, ultimately enhancing your business’s efficiency, customer satisfaction, and overall success.
Understanding Cloud Observability
Let’s start with the basics. Cloud observability is a proactive monitoring approach that helps you get real-time visibility into the behavior and performance of cloud-based systems. It is usually a combination of three key components:
- Metrics: These quantitative measurements capture system-level performance data, such as response times, resource utilization, and error rates. By analyzing metrics, businesses can gain insights into the overall health and performance of their cloud applications and infrastructure.
- Logs: These are detailed records of events and activities within a system and capture information about application behavior, errors, and operational events. They play a crucial role in troubleshooting and post-incident analysis.
- Traces: It is transactional data that follow a specific request or transaction through different components of a distributed system. Traces provide end-to-end visibility, helping to identify bottlenecks, performance issues, and dependencies.
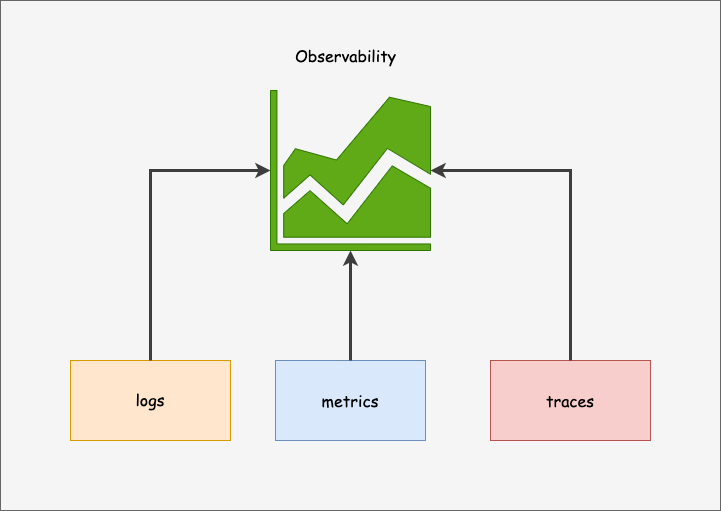
Observability is essential for quickly identifying and resolving incidents. In addition, it helps businesses to minimize downtime, reduce mean time to resolution (MTTR), and mitigate any impact on business operations. Some of the popular tools for cloud observability include:
- Monitoring platforms like Datadog, Prometheus, and others for end-to-end Observability and centralized dashboards.
- Logging & Aggregation Tools like ELK Stack, Splunk, or Grayling help effectively manage log data collection, aggregation, and analysis.
- Tracing Systems like Jaeger, Pipkin, or OpenTelemetry to trace requests across microservices and identify performance errors.
- AIOps platforms like Moogsoft, IBM Cloud Pak for Watson, and others.
As per the 2022 Observability Forecast, 82% of organizations used 4 or more observability tools and still detected 33% of outages manually or from complaints.
Solutions like Middleware can be ideal for businesses that want a more simplified observability process and a unified experience. It acts as a bridge between applications and provides built-in observability features for logging, metrics collection, and tracing across cloud infrastructure.
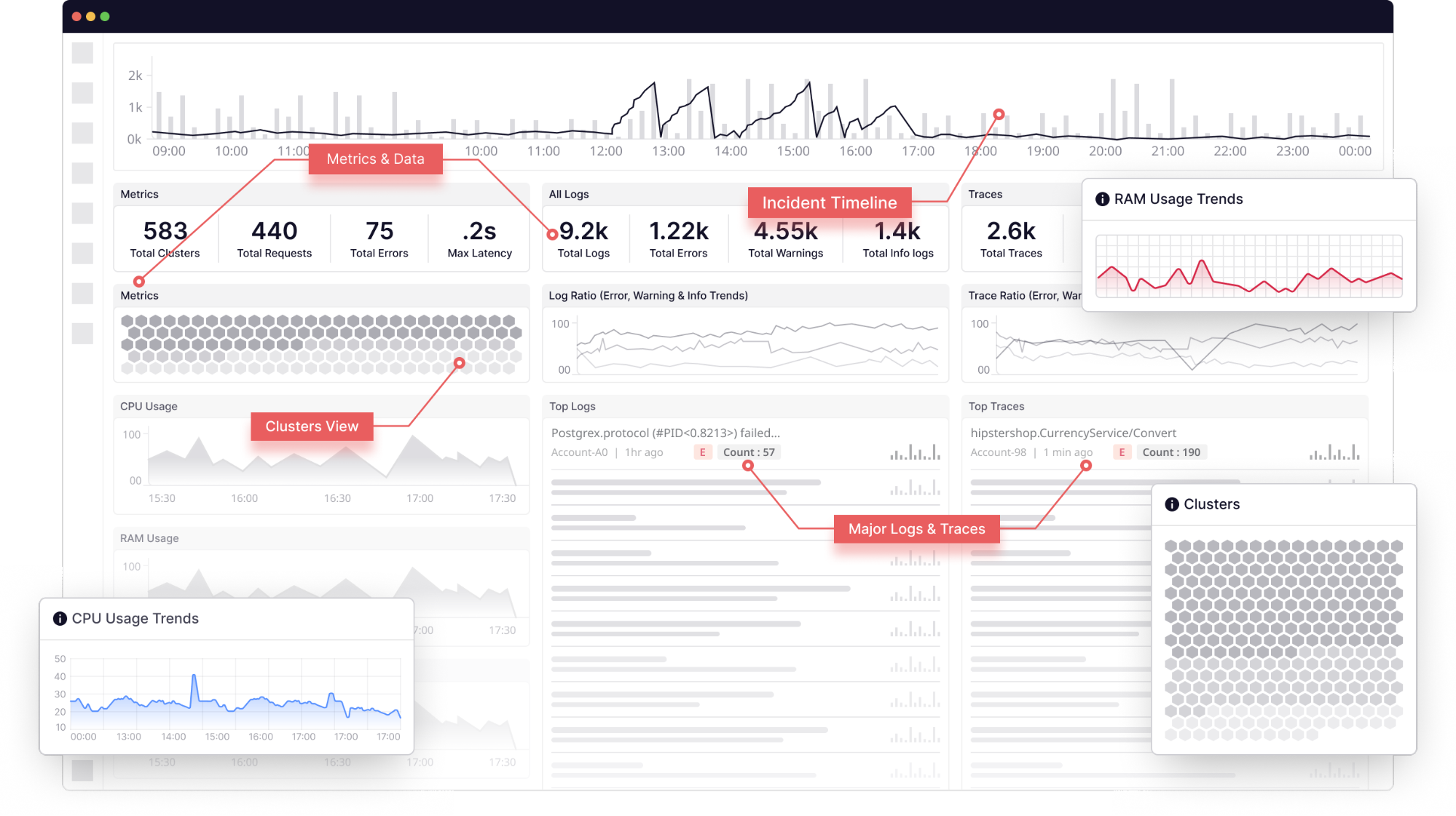
DevOps Processes and Incident Response
DevOps or Development Operations is now a key focus area for most businesses, as it helps ensure effective and efficient processes, including incident response.
DevOps fosters collaboration and communication between development and operations teams, breaking down silos and enabling cross-functional cooperation. This collaboration ensures that incident response is a shared responsibility, with teams working together to detect, diagnose, and resolve issues promptly.
Since Incident Management processes usually involve multiple steps, having clear communication and responsibility helps emphasize continuous improvement and learning from incidents.
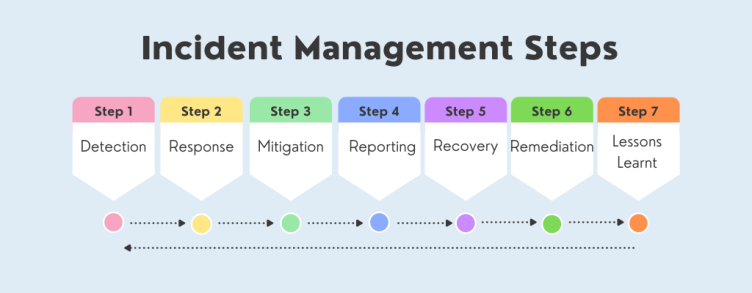
Benefits of Integrating Cloud Observability with DevOps Processes
By integrating cloud observability with DevOps processes, businesses can gain several benefits, such as:
Improved visibility and real-time monitoring through Observability
With cloud observability, businesses can gain comprehensive and real-time insight into cloud-based systems’ performance, behavior, and health. This helps identify gaps and enables the organization to gain real-time insights into metrics, logs, and traces, enabling proactive monitoring and timely identification of anomalies or issues.
Enhanced incident detection and alerting mechanisms
Over 41% of organizations that implemented cloud observability could identify issues in their internal apps within minutes, and this led to a 37% improvement in mean-time detection (MTTD) while bringing down mean time to resolution (MTTR) for incidents by 69%.
Faster incident triaging and root cause analysis
Observability enables businesses to get a clear view of their entire IT infrastructure, which helps DevOps approaches build cross-functional teams and get a holistic understanding of each department. This combination enables advanced detection mechanisms and expedites analysis of incident triaging and root cause.
In addition, businesses can access logs, metrics, and traces quickly, accelerating mean time to acknowledge (MTTA), which improves business operations.
Businesses have also decreased the cost of downtime by over 90% and streamlined the process of finding and debugging incidents since developers can observe the end-to-end journey of a request and get to the root of the issue.
Streamlined incident response workflows through automation
By leveraging automated remediation and orchestration, teams can initiate predefined actions, such as scaling resources, rolling back changes, or deploying hotfixes, ensuring rapid incident resolution and minimizing manual effort.
Achieving a proactive and iterative incident response approach
Integrating cloud observability and DevOps also promotes a proactive incident response approach. By leveraging observability data and conducting post-incident analysis, organizations can identify patterns, trends, and areas for improvement.
This fosters a culture of continuous learning and drives iterative enhancements to incident response processes, resulting in improved efficiency and resilience.
Strategies for Integrating Cloud Observability with DevOps Processes
Implementing Cloud Observability in DevOps workflow is not as simple as it sounds, but there is an ideal approach that your team can follow to make this streamlined and efficient. To do this, follow the steps below:
Select the ideal Observability tool
The key to a successful implementation is selecting the right Observability tool for your need. Ensure you thoroughly analyze the tools available and consider factors like data collection, AI-based insights, real-time monitoring, APIs, and integration with other tools in your tech stack.
Establish clear metrics
Ensure you have a clearly defined key performance indicator (KPI) for your Observability tools. This helps your team to focus on the right objectives and will help provide alerts or suggest improvements to improve this KPI.
Integrate Observability into your CI/CD pipeline
To help detect issues early on, ensure Observability is part of your continuous integration/deployment (CI/CD) process. This will help ensure that your code doesn’t change too much depending on incidents or negatively impact performance.
Invest in training
Observability requires a higher level of expertise and knowledge from your team to be successful. So do not forget to train and upskill your team to ensure they know how to use Observability tools efficiently.
Review & improve
While Observability practices ensure effective and efficient workflows, they are only good if they collect the right metrics and are correctly analyzed. Therefore, make sure to monitor the process and improve regularly using these insights continuously.
Best Practices for Successful Integration
Below is a list of some of the best practices that you should follow when implementing Observability in your DevOps process:
- Don’t try to do too many things simultaneously. Instead, start small and gradually integrate Observability into your workflows.
- Focus on your KPI and metrics first. You can define KPI for each team but ensure it fits the organizational objective.
- Ensure all team members know how to use Observability data for their particular function.
- Continuously monitor everything.
- Do not store all logs and data.
- Enable alerts for critical events only.
- Filter data and create dashboards that are relevant for each team.
- Create custom graphs as per user requirements. Do not just go with the default graphs.
- Integrate Observability tools with your existing systems to automate the process and streamline Observability tasks.
- Foster collaboration and continuous learning. This will ensure that your Observability data is analyzed for continuous improvement.
- Incorporate feedback from relevant stakeholders.
Real-World Examples and Case Studies
Let’s explore how organizations have leveraged this integration to enhance their incident response and achieve operational excellence.
Slack
Slack, which is a widely used communications platform, uses observability to monitor the performance of its application and resolve issues quickly.
With real-time metrics, logs, and traces, Slack’s DevOps teams gain deep insights into their system’s behavior. This allows them to proactively address issues, identify potential bottlenecks, and optimize their platform to deliver uninterrupted communication services.
Result: Since implementing Observability, Slack reduced costs by approximately 70% and decreased error rates by 50%.
Uber
Uber, the global ride-sharing platform, relies on cloud observability to maintain the reliability and scalability of its services.
Through observability tools and practices, Uber gains real-time insights into their distributed system, allowing them to detect anomalies, identify performance issues, and optimize its infrastructure to meet the demands of millions of riders and drivers.
Results:
- Easy management of alerts
- Flexible actions for notifications like paging, emails, and chat
- Automated mitigation for events like rolling back deployments or configuration changes
- Handle high notification volumes using cardinality to scope critical issues
Conclusion
In conclusion, integrating cloud observability with DevOps processes yields substantial benefits for incident response in the cloud environment. Let’s recap the key points:
DevOps combines software development and IT operations to enhance software delivery and reliability, ensuring seamless collaboration between teams.
Observability is a crucial component within the DevOps workflow, providing insights into software behavior, issue identification, and continuous performance improvement.
Observability can be seamlessly incorporated into each stage of the DevOps workflow, including planning, testing, integration, development, operation, deployment, monitoring, and feedback.
Utilizing observability tools allows the collection and analysis of data, enabling the identification of potential issues, system optimization, and continuous improvement of software performance and reliability.
Adopting the industry’s best practices will help you effectively leverage the insights from observability data. This involves carefully selecting appropriate tools, defining measurable metrics and alerts, and promoting a culture of ongoing enhancement. By doing so, you’ll be well-equipped to make informed decisions and optimize your operations for maximum efficiency.