Extract Transform Load (ETL) big data stands for extract, transform and load and is a technology that traces its origin to the mainframe data integration period. Typically, it is a data transfer technology that facilitates for the movement of data from one application database to the next. This completely does away with the need for application programming interfaces (APIs). What this basically means is that it can be possible to bypass an application’s logic, but still be able to access its data layer. While also been in an excellent position of identifying a target location where you can shift such data.
ETL tools
To accomplish this, ETL big data tools are utilized to specify the various data sources along with the distinct procedures for extracting and processing their content. The given tools that are made use of have the responsibility of executing the data transfer process. This essentially makes ETL much more or less identical to programming in conventional meaning of the term. Only instead of using a code editor, you can utilize a graphical user interface. This way you will be able to conveniently specify the rules you wish to use, and at times use drag and drop functionalities to initiate the data flow.
How does ETL work?
The way ETL big data functions is by taking these given rules and running them via an engine, or more to the point, generating coding into executables. The latter of which can be executed within the confines of a specific production environment. Quite a large number of ETL tools carry out their functions in batch mode, as it is where the origins of this data movement technology can be traced. What this really means is there is usually a given event that can initiate the extraction process. On the other hand, it could be a schedule driven process, where the exact schedule set up can determine at what particular moment you can execute a certain data extraction. Additionally, there could also be a set of dependencies for any given schedule. For instance, if the first extract goes on to execute successfully, another one can then be initiated.
What kind of professionals are ETL tools designed for?
ETL tools are primarily designed for data based developers as well as database analysts. This generally equates to an individual who understands big data and databases such as SQL. This is totally unlike application developers who are noted for focusing on procedural coding and 3rd generation programming languages. In ETL around eighty percent of the time the big data is normally extracted from databases.
In what circumstances is ETL big data applicable?
This data movement technology can be particularly excellent when it comes to convenient and stress-free bulk data transfer, which is necessary to do so in batches. Which means it can be ideal for scenarios where you might find yourself working with a set of intricate rules and transformation requirements. To this end, this technology entails a lot of string manipulation, data transformation together with the seamless integration of multiple sets of data from different sources. EPL tools are highly acclaimed for providing connections to libraries along with the integrated metadata sources that lie beneath them. This goes a long way in making big data maintenance and trace-ability much more easier, most especially when you compare it with the scenario of a hand coded environment.
ETL big data as you may have now discovered is a critical data transfer technology that can immensely simplify the process of moving bulk data from one application to another. It at the same time completely does away with the need for APIs to successfully conduct such operations, making it viable even for professionals with minimal programming knowledge. All you simply have to do is set up clear cut rules that you wish to utilize in extracting the data from one application and the ETL tool you use does all the rest.
ETL also goes a step further and facilitates for the convenient reading of multiple types of databases such as web services. While more to the point allowing the pulling together of such data in a highly simplified manner. Should you be a data oriented developer or a database analyst, this big data movement technology can be just what the doctor ordered to immensely simplify your duties.
SAP
Get software and technology solutions from SAP, the leader in business applications. Run simple with the best in cloud, analytics, mobile and IT solutions.
- Support the changing needs of your business
- Access comprehensive business intelligence tools
- Optimize performance across hybrid landscapes
- Reporting and analysis
- Data visualization and analytics applications
- Office integration
HITACHIVANTARA
![]()
Hitachi Vantara brings cost-effective path for your digital transformation with it’s internet of things (IoT), cloud, application, big data and analytics solutions.
- Manage the Analytical Data Pipeline Within a Single Platform
- Support Your Teams in This Rapidly Changing Big Data Environment
- Collaborative Data Prep and Faster Access to Analytics
- Improve Alignment Between Data Engineers and Data Scientists
INFORMATICA
As the world’s leader in enterprise cloud data management, we’re prepared to help you intelligently lead in any sector, category or niche.
- Business and IT collaboration
- Reusability, automation, and ease of use
- Scalability, performance, and zero downtime
- Operations and governance oversight
- Real time data for applications and analytics
- Rapid prototyping, profiling, and validation
- Universal connectivity
- Automated data validation testing
- Advanced data transformation
- Connectivity to Cloud Applications
TALEND
Talend Cloud delivers a single, open platform for data integration across cloud and on-premises environments. Put more data to work for your business faster with Talend.
- Native performance on modern platforms
- Unified environment across on-prem and cloud
- Pervasive data quality from end to end
- Governed self-service
ALOOMA
Bring all your data sources together into BigQuery, Redshift, Snowflake, Azure, and more. Sign up for Alooma Enterprise Data Pipeline Platform for free today.
- Any integration
- End-to-end security
- Managed schema changes
- Never lose an event
- Mapping made easy
- Pipeline transparency
PANOPLY
Panoply is an AI-driven and autonomous cloud data warehouse. With Panoply, you can turn any siloed data into insights in minutes, without additional data engineering resources.
- You won’t find an easier, more useful data warehouse dashboard
- Get tables that are clean, clear and easy to query
- Instantly upload data from any cloud source, database or file
- Panoply connects your data to any BI tool
- Panoply runs on SQL
- Optimize your queries
- Data engineering in a box
- All the help you’ll ever need
BLENDO
Blendo is a self-serve data integration platform that allows you to collect and sync your data with any data warehouse. We make it easy to collect data.
- Self-serve Data Integration
- Connect With Any Data Warehouse
- Historical Data
- Load Schedule
- Data Scheme optimization
- Monitoring
FIVETRAN
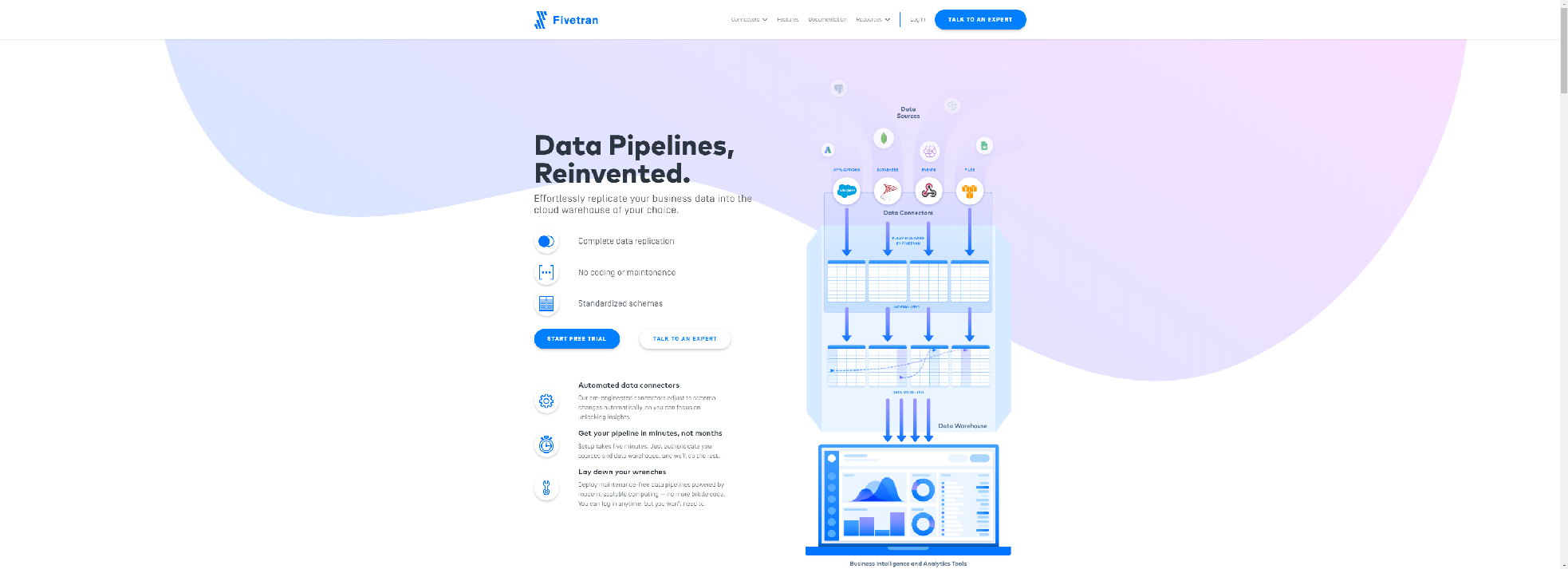
Stream data into your warehouse for advanced analytics. Fivetran was built for analysts to access to all their business data. Sign up today for a free trial.
- Normalized schemas
- Incremental batch updates
- Direct pulls from cloud applications
- 24-hour tech support
- Real-time monitoring
- Battle-tested connectors
- Alerts
- Fully transparent, totally responsive
- Granular system logs
- Automatic schema migrations
- Guaranteed data delivery
- Efficient cloud-to-cloud replication
SEGMENT
Segment is a customer data infrastructure (CDI) platform that helps you collect, clean, and control your customer data.
- Simplify data collection with a single API
- Integrate 200+ tools with the flip of a switch
- Manage data across your business
- Security and privacy built in
AZURE.MICROSOFT
Azure Data Factory is a hybrid data integration service offering a code-free experience. Extract data from heterogenous data sources, transform it at cloud scale with the Mapping Data Flow feature (now in preview), publish it to any analytics engine or business intelligence tool, and monitor and manage your data pipelines.
- Visual drag-and-drop UI
- SSIS migration to cloud
- Comprehensive orchestration
- Multiple language support
- Hybrid data movement and transformation
CLOVERDX
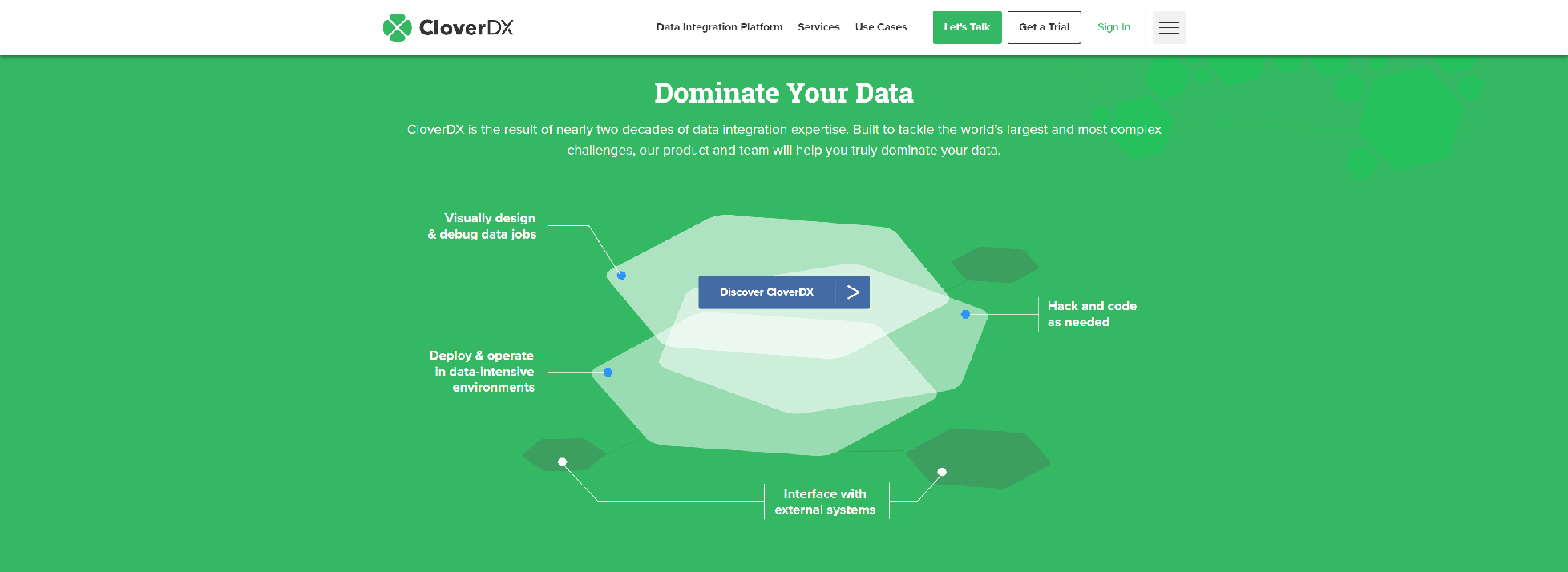
CloverDX is a data integration platform for designing, automating and operating data jobs at scale. We’ve engineered CloverDX to solve complex data scenarios with a combination of visual IDE for data jobs, flexibility of coding and extensible automation and orchestration features.
- CloverDX helps you tackle the simplest and the most complex tasks with complete confidence
- The most basic transformations can become operationally complex
- Advanced transformations and operational environments