Computer vision started in the 1960s to mimic the function of the human eye and is now a rapidly advancing technology, that links the digital and physical world. Nowadays computer vision has become a part of our lives and is a blessing that is helping people stay connected in hard times of social distancing due to covid. From endless Snapchat filters to zoom classes, meetings, and video calls to loved ones we are one click away to see the world.
OpenAI
OpenAI is a leading AI-based research and development company, with a mission to create a positive impact on society through its efforts to achieve human-level artificial intelligence. Despite its small existential period of six years, it’s a company that takes the limelight due to its contribution to advancement in artificial general intelligence AGI. OpenAI started 2021 with its gift to the world of computer vision through its two major innovations CLIP along with DALL-E. [1]
What’s CLIP
Contrastive Language Image Pre-training (CLIP) [2] is a neural network that takes the image classification a notch up. Usually, the vision models are task-specific and if the same models are required for another task, we have to tailor them precisely according to the demands of the project, which demands both financial and human resources. While in CLIP, any visual classification task can be performed by providing visual categories along with their names. Moreover, we can design our own classifier. Similar to GPT-2 and GPT-3 the “zero-shot” learning model is implied. The class of even those image samples can be predicted by the algorithm, which it has not come across during the training of visual data. Moreover, collection of the training data is expensive and time-consuming while CLIP can be trained easily through the pairs of visual data and their description available online. [3]
Zero-short prediction
The classification of unseen data using zero-short [4] is something that has been done previously. Whereas the application of this concept to the classification of visual data is something new. With the currently available models for computer vision, training data is task-specific, and to carry on with various tasks same datasets cannot train the model. Unlike that, CLIP has approached zero-short from a new and interesting angle. There is no need for specific training data. Images paired with their title available on the internet can be used to predict outcomes.
Algorithmic Approach
CLIP models are trained on widely available online data as natural language is considered a predictor. So, depending upon the function to be performed, the models can be applied to various vision tasks. From the dataset containing 32,768 images with their related text, the CLIP model was trained to match the unseen test image with its paired label from the selected dataset. Open AI has divided its classification process into three steps figure below.
- The available dataset is used for the training model by matching the images with the title that best describes the images.
- Next, all the text is converted to captions so after detecting the class of test image the image can be described clearly.
- After this, the zero-short predictions are made. A new image belonging to a related class is selected and is tested against the text encoded in the second step. After classification, the system links the visual data to its class. A caption is allocated to the image based on the estimations.
- Contrastive pre-training creates a dataset classifier from label text use. Zero-shot prediction.
Classification Overview
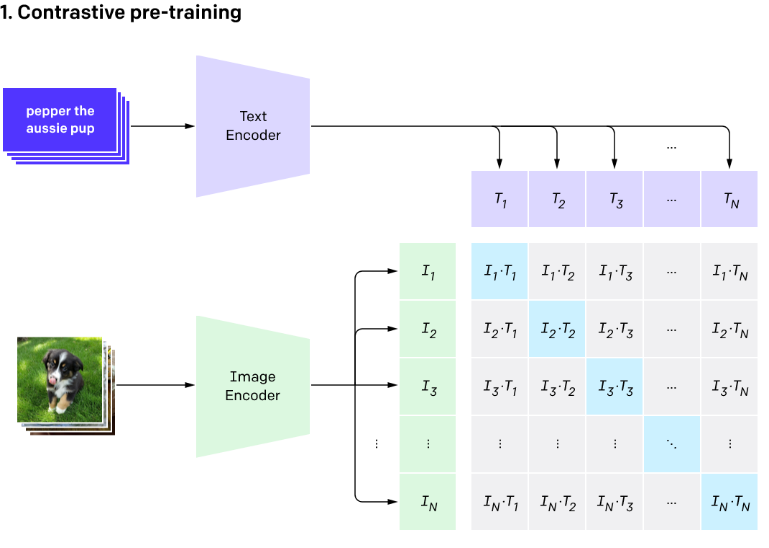
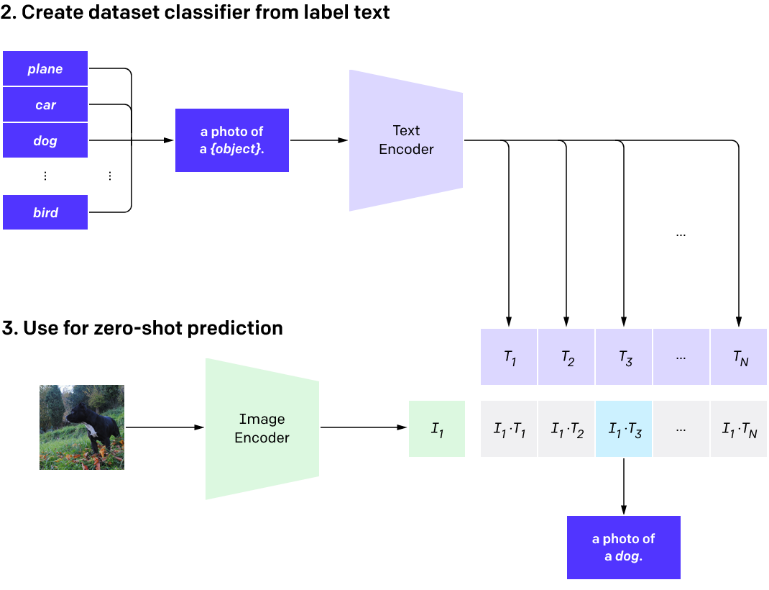
Addressing barriers
Through CLIP, two major obstacles that are faced whilst the application of a standard deep learning approach to computer vision are overcome. [5]
- Expensive datasets: Vision training require labeling of data which is done manually. The cost of datasets outstrips because large numbers of training samples are necessary to train a model. To explain this, we can consider the example of the ImageNet dataset 14 million images were acquired for 22,000 object classes. They employed 24 thousand of workers to acquire visual data.
- Narrow range of categories: Despite training the ImageNet model on 22 thousand object classes, the classification of unseen data is a task beyond capability. Moreover, a machine learning model may perform specific work with high accuracy but when the same model is utilized for another task its performance deteriorates.
Highlights about CLIP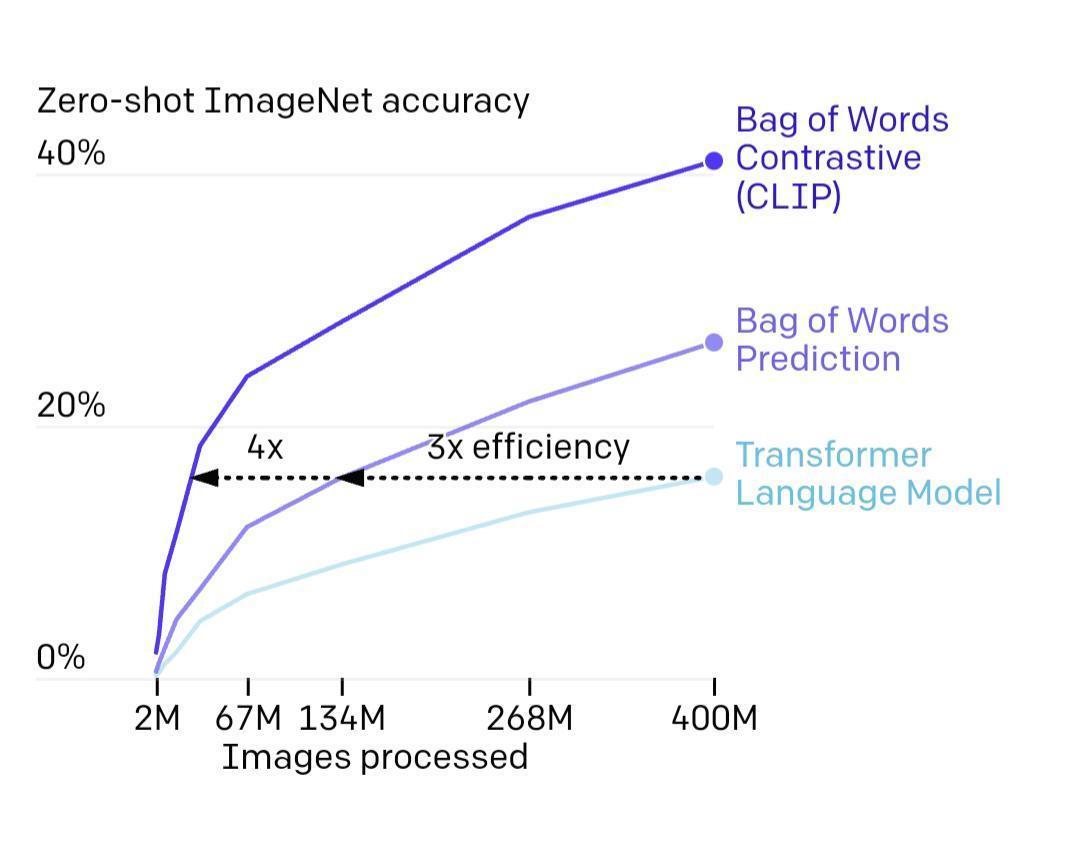
The key features that distinguish CLIP from other deep learning models include:
- Can work on unfiltered and highly noisy data in terms of training data, the Model adjusts itself based on tasked performance.
- CLIP model’s performance when compared with the best currently available models like ImageNet model, the Noisy Student EfficientNet-L2, and various others, CLIPS model outshined them.
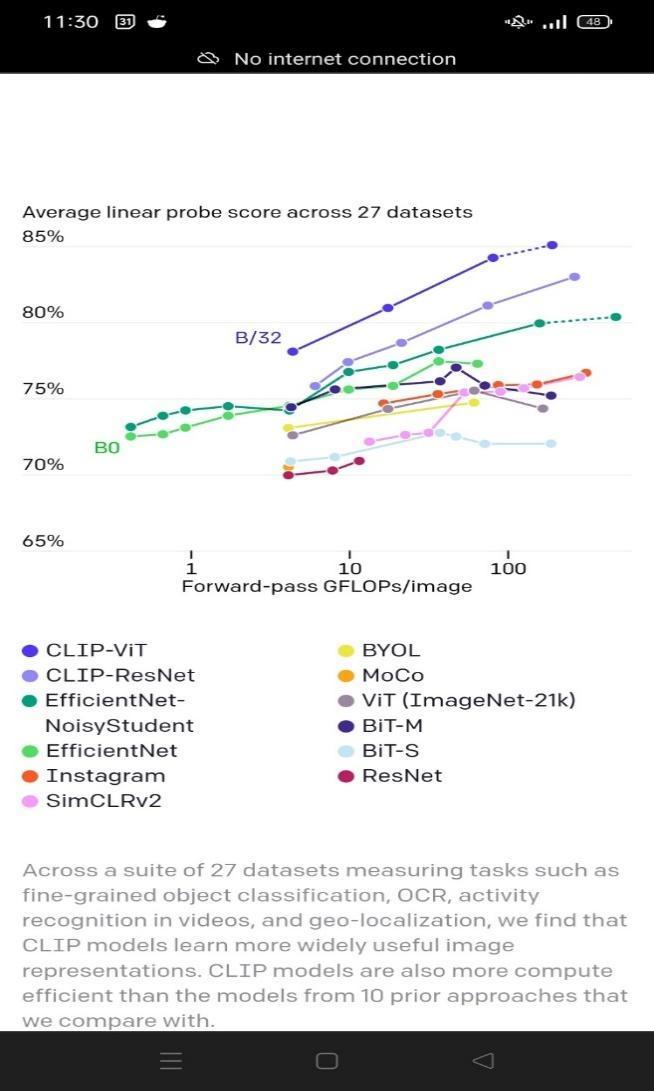
- While comparison with other models the liner probe score depicts the greater accuracy of the CLIP-vit model as shown in the figure.
- Four hundred million images were used to train the model and zero-short predictions were applied. As it can be visualized here. The accuracy of the system along with the efficiency of the model is impressive.
- Some areas that require work in the future are that CLIP is disgusting multiple objects in the same image. Also, in comparison with task-specific models, more efforts are required to enhance their performance.
Future work
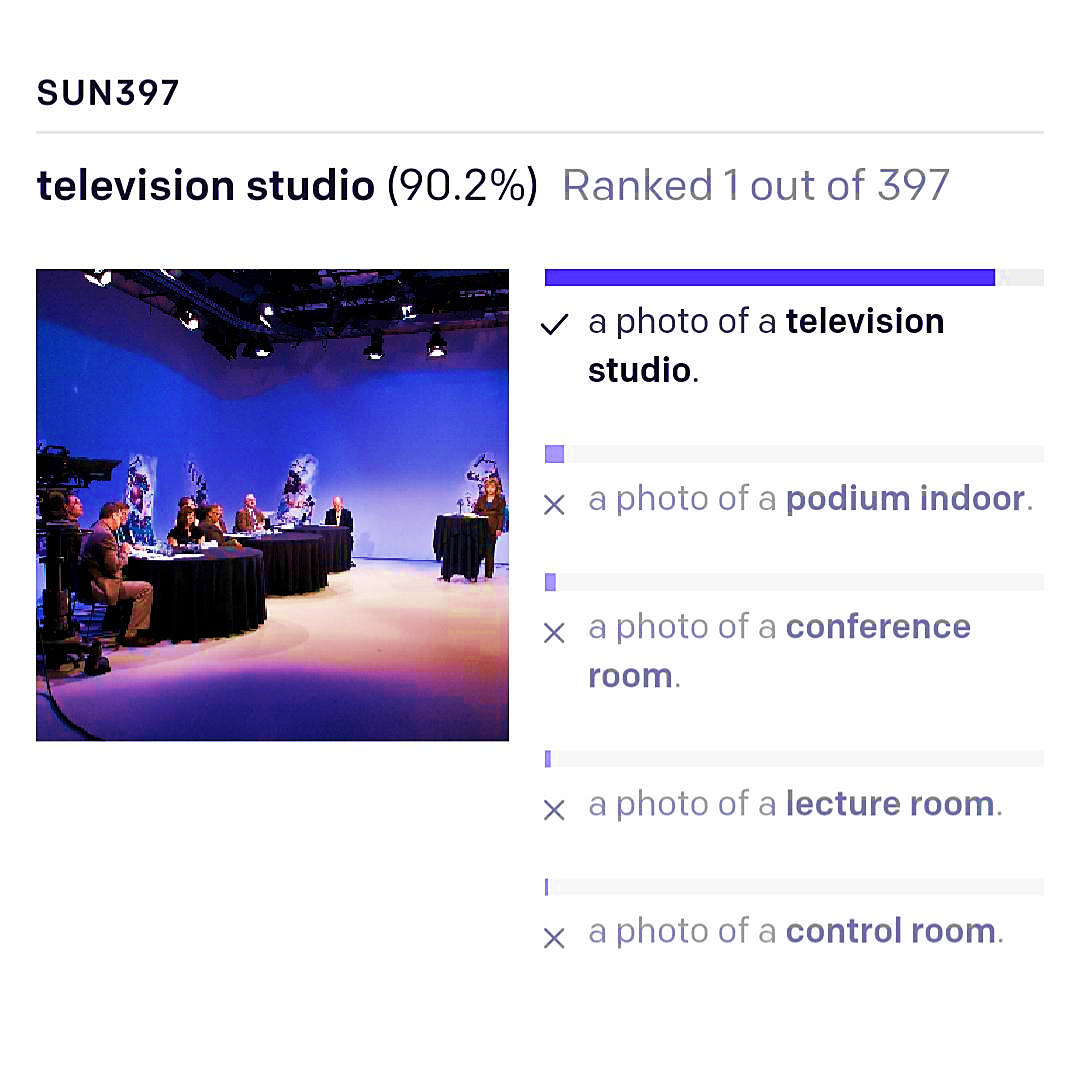
Limitation related to heavy costs was ruled over by CLIP in a way that it can work on the image-text pairs available online. Additionally, this type of data is unimpeded and free of cost. Eliminating the expenses of labor and saving time that goes into labeling visual data. As far as the second problem is concerned, CLIP implies zero-short predictions. As the model works on normal language supervision so for performing multiple operations the same model can be used. The classification accuracy of CLIP can be visualized in the fig1 where the image of a television studio is paired with its description.
Conclusion
To sum everything up we can say that the CLIP approach is a step taken by OpenAI that will change the future of computer vision. Zero-short predictions in the CLIP model have paved the way for researchers to work on solving problems without worrying about costly and time-consuming training datasets. This model can be fine-tuned and applied in different fields for performing visual tasks.
References
A. Radford, J. Kim, C. Hallacy, … A. R. preprint arXiv, and undefined 2021, “Learning transferable visual models from natural language supervision,” arxiv.org, Accessed: Jan. 14, 2022. [Online]. Available: https://arxiv.org/abs/2103.00020.
O. Keyes, “The misgendering machines: Trans/HCI implications of automatic gender recognition,” Proc. ACM Human-Computer Interact., vol. 2, no. CSCW, Nov. 2018, DOI: 10.1145/3274357.
R. Geirhos, P. Rubisch, C. Michaelis, … M. B. preprint arXiv, and undefined 2018, “ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness,” arxiv.org, Accessed: Jan. 14, 2022. [Online]. Available: https://arxiv.org/abs/1811.12231.
S. Dodge, L. K.-2017 26th international conference on, and undefined 2017, “A study and comparison of human and deep learning recognition performance under visual distortions,” ieeexplore.ieee.org, Accessed: Jan. 14, 2022. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/8038465/.
M. Alcorn, Q. Li, Z. Gong, … C. W.-P. of the, and undefined 2019, “Strike (with) a pose: Neural networks are easily fooled by strange poses of familiar objects,” openaccess.thecvf.com, Accessed: Jan. 14, 2022. [Online]. Available: http://openaccess.thecvf.com/content_CVPR_2019/html/Alcorn_Strike_With_a_Pose_Neural_Networks_Are_Easily_Fooled_by_CVPR_2019_paper.html.