We are on the verge of transitioning to the age of cloud computing, where every small and big organization wants to access their data despite location and time constraints. In today’s digital world, the most profound demand for businesses is any time data. To set up multiple servers and machines, businesses needed to expand and transfer all the data to servers at different locations. But don’t you think it will be costly?

That’s when the cloud comes in. With swiftly available resources that can be used by any firm, large or small. The big names in cloud are AWS, IBM, and Google; most companies rely on them for cloud related services and solutions. If you know about the cloud, you must have heard about containerization, orchestration, microservices and many more. In this blog we will specifically discuss containers, containerization and Kubernetes.
What are containers, and what are they used for?
Containers are software units that are packed with all the necessary elements to function in any environment. They virtualize the operating system and can run from anywhere. Although containers offer many benefits, they also require management and connectivity to the outside world for additional operations like distribution, scheduling, and load balancing. From Gmail to YouTube, everything is running in containers. Now, how to manage it? That’s where Kubernetes comes in. Kubernetes is a unquestioned pioneer in container orchestration. So,if you are talking about containers understand Kubernetes is always there.
What is Kubernetes?
Kubernetes is an extendable open source platform. It is used to manage containerized workloads and services. It facilitates automation and declarative configuration. The Kubernetes ecosystem is vast and is rapidly growing as it’s services, tools and support is everytime available.
Kubernetes is a Greek word that means “helmsman” or “pilot.” K8s is derived from counting the eight letters between the “K” and the “s.” Google released the Kubernetes project as open source in 2014. Kubernetes combines over 15 years of Google experience running production workloads at scale with best-of-breed community ideas and practices. Below is an image showing how deployment has changed so far:
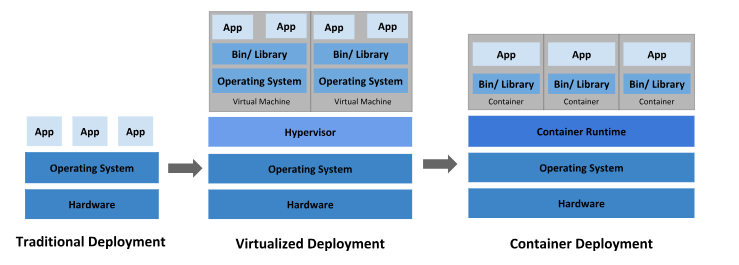
Why is Kubernetes loved by all?
Let’s understand why Kubernetes is getting immensely popular:
1. A Complete Open Source Platform
The most distinguishable feature of Kubernetes is that it is the only container orchestration platform that is completely open source. This means that the source code is public, and anybody can modify, view, use, and customize it. This transparency helps build a collaborative community of businesses, developers, and cloud enthusiasts who work together to develop and expand the Kubernetes ecosystem. Open-source software offers transparency and confidence by allowing users to review the code for security and quality assurance. Furthermore, it encourages creativity by allowing users to design and share innovative solutions that can extend Kubernetes to fit specific requirements.
2. Kubernetes can run Anytime, Anywhere
Kubernetes was created to be adaptable and portable. It can be installed and used practically anywhere, including private on-premises data centers, public cloud environments like as AWS, Azure, and Google Cloud, as well as at the edge in distributed computing topologies. Because of this flexibility, businesses can choose the deployment location that best fits their demands, whether they be scalability, compliance, data residency, or other criteria. Because of Kubernetes’ “Anytime, Anywhere” characteristics, applications may be managed and controlled reliably across diverse infrastructure environments.
3. Kubernetes is completely managed through code
The idea of controlling infrastructure and application resources through code, or “Infrastructure as Code” (IaC), is one that Kubernetes supports. Declarative configuration files in the YAML or JSON formats are used by users to specify the desired state of their Kubernetes clusters and apps. These configuration files outline what ought to be operating, how it ought to be set up, and the intended condition. Infrastructure becomes versionable, reproducible, and automatable by using code to manage Kubernetes. Additionally, this method makes it simpler to track revisions, collaborate on infrastructure improvements, and minimize human error, increasing Kubernetes clusters’ overall dependability and maintainability.
4. Kubernetes is very extensible
Due to its highly extensible architecture, Kubernetes offers a platform for integrating new tools and services as well as adding customized functionality. Its API-driven design, which enables users to build custom resources, controllers, and operators to automate operations particular to their applications or infrastructure needs, enables extensibility. Kubernetes is a versatile platform that can be customized as per the requirements. It has so many plugins, extensions, and integrations that it is super extensive. It continuously adapts to new technologies and addresses the challenges of managing and delivering applications.
Kubernetes: Structure Tour
The managed Kubernetes cluster operates in two architecture; one is worker, the other is master. The master manages all the management tasks and dispatches them to the appropriate Kubernetes work nodes as per the requirements. Let’s have a structure tour of Kubernetes architecture.
1. Node: The Kubernetes cluster’s nodes, sometimes referred to as workers or minions, are real or virtual machines where containers are installed and run. Running containerized applications and delivering resources like CPU, memory, and storage fall under the purview of nodes.
The following elements are found in each node:
- Kubelet: To make sure containers are executing in a Pod exactly as intended, the Kubelet is an agent that runs on each node and interacts with the control plane (the Kubernetes master).
- Container Runtime: Different container runtimes, including Docker, containerd, and CRI-O, are supported by Kubernetes. Executing container images on the node is the responsibility of the container runtime.
2. Pod: A Pod, which stands for a single instance of a containerized application, is the smallest deployable unit in Kubernetes. The network namespace that all containers in a pod share is localhost, which they can use to connect with one another. The control plane plans when pods should be placed on nodes.
3. Service: A set of Pods and a policy for accessing them are defined by services. They provide load balancing and service discovery while serving as a reliable endpoint for contacting the application. Different service types, such as ClusterIP, NodePort, and LoadBalancer, are supported by Kubernetes.
4. Volume: Volumes are used to persist data in Kubernetes. They can be mounted into a Pod and provide a way for containers to access and store data. Kubernetes supports various types of volumes, including hostPath, Persistent Volumes (PVs), and Persistent Volume Claims (PVCs).
5. Namespace: A Kubernetes cluster can be logically divided and isolated using namespaces. They permit the use of a cluster by several users or teams without interfering with one another. Kubernetes comes with a “default” namespace by default, but you can make your own namespaces for various uses.
6. Control Plane (Master): The Kubernetes cluster’s control plane, which governs the cluster’s general state and orchestration, is its brain. It includes various important parts, including:
- API Servers: Users and other components can communicate with the cluster by using the API server, which is the front-end component that exposes the Kubernetes API.
- Etcd: A distributed key-value store called etcd is where the cluster’s configuration information and current state are kept. It serves as the database for the cluster.
- Controller Manager: The controller manager keeps an eye on the cluster’s condition and makes sure the desired state is preserved. Replication, endpoints, and other resource controllers are included.
- Scheduler: Based on resource limits, resource requirements, and affinity/anti-affinity rules, the scheduler places Pods onto nodes.
7. KuberProxy: A network proxy called Kube Proxy runs on every node and keeps track of the network settings there. Network communication to and from the Pods and services is made possible by it.
8. Add ons: Clusters using Kubernetes frequently have extra add-on components for logging, monitoring, and other uses. Examples are Fluentd for logging and Prometheus for monitoring.
Conclusion
For managing full stack operations and containers, utilize Kubernetes, an open-source container. Discover how Successive can help you with Managed Kubernetes Consulting services For Enterprises and Startups. The legacy software program must be re-platformed, re-hosted, recoded, rearchitected, re-engineered, and made interoperable in order to be migrated to cloud-native application architectures. Migration of monolithic programs to the new Microservices architecture is made possible by application modernization services. Install your Big Data Stack Infrastructure there and manage it.